Op 10 juli 2015 bereikte ons het feestelijke nieuws dat de rijksbrede inventarisatie was afgerond. Een traject waar ook Open State zich actief voor heeft ingezet. In totaal 550 (om precies te zijn 548) datasets zijn volgens de Kamerbrief online te vinden. Een enorme stap, na de Verenigde Staten en Groot-Brittannië is Nederland het derde land dat zich inzet voor een rijksbrede inventarisatie.
Van de 944 datasets zijn er momenteel 548 beschikbaar, 200 in onderzoek, 84 zijn er ‘gepland’ en 112 gesloten. De komende weken neemt Open State de inventarisatie verder onder de loep. In deze blogpost toetsen we de eerste resultaten van de inventarisatie aan de Leidraad Open Data (openbaarheid, toegankelijkheid en vindbaarheid). Een eerste oordeel: we zijn goed op weg, maar het kan nog heel veel beter!
1.Er kan nog (veel) meer bij!
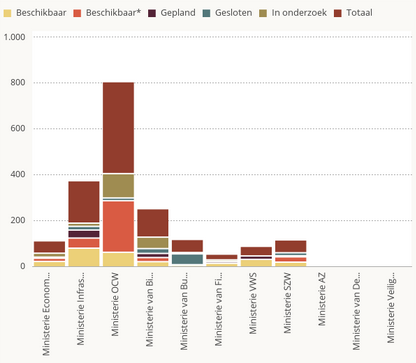
Uit de inventarisatie blijkt dat er 944 datasets zijn binnen de Rijksoverheid. Het is voor het publiek niet duidelijk op basis waarvan datasets zijn geselecteerd, welke sets wel of niet geschikte als open data zijn beoordeeld, maar zeker is dat er een aantal grote datasets mist. (Waarom is bijvoorbeeld het handelsregister van de Kamer van Koophandel niet opgenomen?).

Als we kijken naar welke ministeries het meeste aanbieden, dan steekt het ministerie van Onderwijs, Cultuur en Wetenschap met kop en schouders boven de rest uit, gefeliciteerd! Het ministerie van Buitenlandse Zaken loopt achter, zij opent een matige 3 van de 57 datasets. Maar de kroon spannen het ministerie van Veiligheid en Justitie, Algemene Zaken en Defensie. Deze drie ministeries ontbreken geheel in de inventarisatie.

2. Wees preciezer over geplande datasets
Op data.overheid.nl wordt aangekondigd dat dit jaar nog 84 datasets beschikbaar worden gemaakt (status=gepland). Dat klopt volgens onze overzichten niet. Van de 84 geplande sets worden er volgens de planning 72 nog dit jaar opgeleverd: één in 2016, één in 2017, vijf in 2018. Van één andere dataset is de planning onbekend en van vijf sets is aangekondigd dat ze in 2018 beschikbaar zijn. Tot slot staat er bij vier sets aangedragen door het ministerie van Financiën, als status “besluitvorming”. Hieruit blijkt dat de openstelling niet gegarandeerd is.
3. Leg meer uit
Van 112 datasets is het zeker dat deze gesloten blijven, oftewel: niet voor publiek hergebruik beschikbaar komen (status=gesloten). Volgens ons is transparantie ook uitleggen waarom je de data niet kunt of wil vrijgeven. Wanneer datasets niét worden geopend met als enige toelichting één van de onduidelijke kopjes gevoelig (1), onbekend (4) of staatsveiligheid (1) verwachten we toch wat meer toelichting.
Opvallend vaak wordt privacy als argument gebruikt om datasets niét te openen. Van de 103 gesloten datasets wordt er bij 94 datasets aangegeven dat dit gebeurt omwille van privacy. Maar is dit écht allemaal privacygevoelige informatie? En kan een deel daarvan niet geanonimiseerd worden aangeboden, zoals bijvoorbeeld de culturele subsidies? In Subsidietrekker heeft Open State al aangetoond dat overzichten van subsidies prima geanonimiseerd kunnen worden.

4. Onvolledige datasets zijn ook geen open data
Wanneer slechts een deel van een dataset wordt aangeboden is dit volgens ons ook niet transparant. Een mooi voorbeeld hiervan is TenderNed, waar aanbestedingen te volgen zijn. Binnen de aangeboden set zijn alleen de laatste 25 sets te zien. Hiermee is het onmogelijk om een analyse te maken op basis van historie. In het maar deels aanbieden van datasets schuilt een gevaar: ondoorzichtigheid wordt in de hand gewerkt door de indruk te wekken dat er een volledige set aangeboden wordt, terwijl er maar een selectie geopend blijkt.
5. Veel data matig toegankelijk
Open data worden zo goed mogelijk beschikbaar gesteld zodat programmeurs of andere gebruikers er naar eigen inzicht mee kunnen werken. Dat betekent dat ze beschikbaar “as is”: zonder registratie toegankelijk, zo volledig en ruw als mogelijk, vrij van rechten, voorzien van metadata en computer verwerkbaar. Alleen dan zijn ze bruikbaar voor interessante analyses. Steekproefgewijs hebben we de links naar datasets getest. En wat blijkt: we vinden een hoge dosis zoekmachines, pdf’s, en logs op kaarten (niet in open format). Dit staat hergebruik in de weg.

6. De meeste data staan nog niet op data.overheid.nl
Op data.overheid.nl zijn nu 222 datasets te vinden. Dat is 24% van alle aangeboden data en 326 sets staan nog her en der verspreid. Dat is jammer. Voor de vindbaarheid van open data is een centrale plek (data.overheid.nl) essentieel.
7. Tot slot: focus op transparantie over het proces
Het resultaat van de eerste inventarisatie – 548 datasets – is een prima begin. Het open stellen van data is immers een ongoing process. Wat er volgens Open State beter kan, is de transparantie over het proces. Open State ziet graag dat niet enkel jaarlijks, maar doorlopend gerapporteerd wordt over de voortgang. Een mooi voorbeeld daarvan is gemaakt door de Amerikaanse counterpart van data.overheid.nl, Project Open Data Dashboard waar ambtenaren hun openstellingsproces online bijhouden, maar waar bijvoorbeeld ook de impact van het openen van de data wordt bijgehouden. Wellicht een mooie manier om data.overheid.nl nóg beter te maken?
Voor nu zien we dit als de start van een voortdurend proces en kijken halsreikend uit naar de volgende update in het najaar!