On the 10th of July we received the joyful news that the first government-wide data inventory was finished. A trajectory for which Open State has actively applied itself. According to the letter for the Dutch parliament a grand total of 548 datasets can now be found online. A giant leap. After the United Kingdom and the United States, the Netherlands is the third country to have a government-wide data inventory.
Of the 944 datasets 548 are available (‘Beschikbaar’), 200 are under investigation (‘In onderzoek’), 84 are ‘planned’ (‘Gepland’) and 112 are closed (‘Gesloten’). In the upcoming weeks Open State will take a closer look at the inventory. With this blog we are checking the first results of the inventory with the Dutch Guideline Open Data (openness, accessibility and findability). Our first judgment: we are on the right path, but there is room for improvement!
1. (Much) more can be added
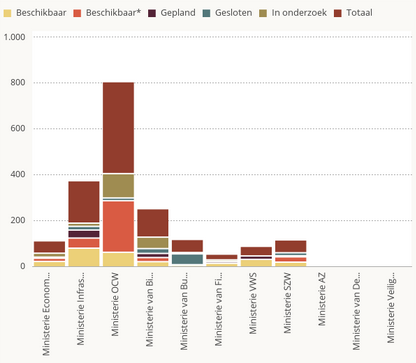
The inventory states that the Dutch national government holds 944 datasets. For users it is not clear what the selection criteria were: which sets are or are not suitable to be released as open data? It is certain that a lot of datasets are missing (Why is the trade register of the Chamber of Commerce not included for example?).

If we have a look at the ministries that offer most datasets, the Ministry of Education, Culture and Science is the absolute winner. The Ministry of Foreign Affairs is lagging, they will just open 3 out of 57 datasets. But what strikes the most are the Ministries of Security and Justice, General Affairs and Defense. These three Ministries are completely absent in the inventory.
2. Give more information about upcoming datasets
An announcement on data.overheid.nl states that this year 84 datasets will be made available (status = planned). According to our overview this is incorrect. Of the 84 upcoming datasets only 72 will be made available this year: one in 2015, one in 2017, five in 2018 and for one set the status is ‘unknown’. Finally, four datasets of the Ministry of Finance are listed as “to be decided upon”. This means that publication is not guaranteed.
3. State and explain
112 of the datasets are listed as closed, or: will not be published for re-use. According to us, transparency also means that you have to explain why you are not willing or able to release the data. When datasets cannot be released we expect more clarification then just the words sensitive (1x), unknown (4x) or state security (1).
A lot of times privacy is used as an argument not to open a dataset. Out of 103 closed datasets, 94 cannot be opened because of privacy reasons. But is it really impossible to publish the data because of privacy concerns? Is it not possible to anonymize parts of the data, as for example the cultural subsidies? With Subsidietrekker Open State showed that overviews of subsidies can be published anonymous.
4. Incomplete datasets are not open data
When just a part of the dataset is available it is not transparent according to us. A good example is TenderNed, where you can follow public tenders. The offered set only shows the last 25 sets. This makes it impossible to make a complete analysis.
5. A lot of data is not really accessible
Open data means that developers and other users can do with the data whatever they want. That means that the data is available as is: accessible without registration, as complete and raw as possible, free of copyright, the metadata is included and the data is machine readable. Only then the data can be used for interesting analyses. We checked the links to the datasets based on a random sample. We found a large amount of search engines, pdf-documents, logs on maps (not in an open format). This a is barrier for re-use.

6. Most data not available at data.overheid.nl
You can find 222 datasets on data.overheid.nl. That is 24% of the available data en 326 are scattered on other websites. That is a pity. For accessibility and findability a central platform (data.overheid.nl) is essential.
7. Last but not least: Focus on process transparency
The result of the first inventory – 548 datasets – is a good start. After all, opening up data is an ongoing process. According to Open State the process can be made more transparent. Open State would like to see not only an annual, but continuous progress reports. A good example is the American counterpart of data.overheid.nl, Project Open Data Dashboard. On this website civil servants can update the process of their opening up of the data. Would that not be a great way to improve data.overheid.nl?
For now, we see this as the start of an ongoing process a look forward to the next update of the government-wide data inventory.