
Wie schrijft positief of juist negatief over klimaat, mantelzorg of hondenpoep? Kun je op geautomatiseerde wijze, betrouwbare uitspraken doen over de sentimenten in pers- en nieuwsberichten van lokale politieke partijen? Dat is wat onze stagiair Ludi van Leeuwen de afgelopen drie maanden onderzocht. Hier vertelt ze over haar bevindingen.
Mijn naam is Ludi, vierdejaars student filosofie en kunstmatige intelligentie aan de Rijksuniversiteit Groningen. De afgelopen drie maanden heb ik stage gelopen bij de Open State Foundation. Ondanks de rare Corona-tijd, heb ik het erg naar mijn zin gehad.
Tijdens mijn stage heb ik gewerkt aan een nieuwe versie van PoliFLW’s sentiment-analyse. PoliFLW is een Open State-platform dat alle berichten van (bijna) alle lokale politieke partijen verzamelt, een goudmijn aan data dus. Sentiment-analyses zijn interessant omdat ze, zeker op grote schaal, inzicht zouden kunnen geven in de uitingen van lokale politieke partijen. Dit blog legt uit hoe sentiment-analyse werkt (en niet werkt), de problemen waar ik tegenaan liep tijdens het bouwen en wat je er uiteindelijk toch mee kan doen.
Positief, negatief of neutraal
Je kan een sentiment-analyse gebruiken om te zien of een tekst positief, negatief of neutraal is. Als lezer doe je dit eigenlijk intuïtief al: gebruikt de schrijver veel bijvoeglijk naamwoorden of schrijft ze juist heel vlakjes en neutraal? Dit kan je bekijken over de hele tekst en zo kan je een hele tekst classificeren als positief, neutraal of negatief.
Je kan ook verder inzoomen: Niet de hele tekst maar juist sentimenten op bepaalde onderwerpen analyseren: dezelfde schrijver kan neutraal schrijven over de opening van een cultureel centrum in het dorp, heel positief schrijven over het geweldige nieuwe ecoduct, en juist heel negatief over die afschuwelijke hondeneigenaren die de vieze drollen van hun luidruchtige hond niet opruimen. De sentimenten geven aan hoe de schrijver over de onderwerpen denkt.
Geautomatiseerde sentiment-analyse
Je kan sentiment-analyse met de hand doen, maar dat is tijdrovend en daarom heb ik twee niveaus van sentiment-analyse geautomatiseerd: binnen Poliflw zelf krijgt een hele tekst een classificatie van positiviteit en subjectiviteit, door middel van een API. Op wie.poliflw.nl kan je de sentimenten op specifieke onderwerpen analyseren. Jij selecteert een onderwerp, de sentiment-analyser vindt de teksten in Poliflw die relevant zijn en toont je de gevonden sentimenten op die onderwerpen.
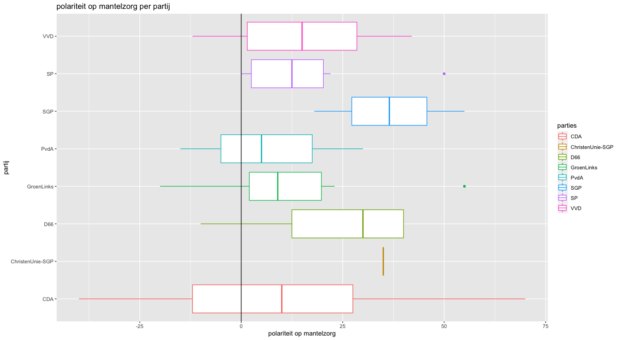
Een voorbeeld: Als je zou willen weten hoe verschillende partijen denken over het onderwerp ‘mantelzorg’, kan je die term op wie.poliflw.nl invoeren en kiezen hoeveel berichten je wilt meenemen in je analyse. Daar komt een csv-bestand (spreadsheet) uit, waar je vervolgens de mediaan polariteit (hoe positief of negatief iets beschreven wordt) op het woord ‘mantelzorg’ kan bepalen, per politieke partij.
Zo is in onderstaande grafiek te zien dat partijen verschillende mediaan polariteiten hebben op ‘mantelzorg’. De SGP is het meest positief, met een mediaan polariteit van ongeveer +37 (polariteit gaat tussen de -100 voor negatief en de +100 voor positief). De andere partijen lijken minder positief dan de SGP – de PvdA met een mediaan van ongeveer +10 het minst. Voor de goede orde: Dit zijn dus de sentimenten op ‘mantelzorg’ geanalyseerd op 200 berichten.
‘De gemeenteraad verroert geen vin’
Het is belangrijk om te vermelden dat mijn sentiment-analyse zoals hij nu is, niet goed genoeg is om serieuze conclusies te trekken over het taalgebruik van politieke partijen. De analyse mist nog te veel aspecten die taal zo leuk en divers maken en pakt alleen eenvoudige, makkelijk te herkennen sentimenten op (en zelfs dat niet altijd op een goede manier).
Deze sentiment-analyse daarom gezien worden als een tool om onderwerpen te verkennen, en om te kijken of er interessante patronen zitten in de berichten van politieke partijen. Het is geen methode die leidt tot betrouwbare, statistisch-onderbouwde conclusies. Daarvoor is gewoon nog niet genoeg waterdicht.
Hieronder wat voorbeelden die de gebreken van de sentiment-analyse demonstreren:
- Spreekwoorden en ironie. ‘De gemeenteraad verroert geen vin’, lijkt mij een overwegend negatief sentiment maar dit wordt niet opgepakt in de analyse. En ook in deze tekst, kan mijn sentiment-analyse niet begrijpen dat ‘dom volkje’ ironisch is bedoeld.
- Uitgespreide sentimenten: ‘Een nieuwe kerncentrale in ons dorp? Dat nooit’, wordt niet opgevat als een negatief sentiment rond het onderwerp ‘kerncentrale’, omdat ‘kerncentrale’ en ‘dat nooit’ in twee verschillende zinnen staan. En met de zinnen: ‘een nieuwe kerncentrale in ons dorp? Over mijn lijk!’ zal de sentiment-analyse al helemaal niks kunnen.
- Foutpositief – een sentiment zien waar het niet is: Het woord ‘naar’ wordt vaak door de Spacy-zinsontleder (https://spacy.io ) gezien als een sentiment. Denk aan ‘een nare man”, in plaats van ‘ik ga naar de bank’. De bank is, in dit fragment tenminste, niet ‘naar’.
- Foutnegatief – geen sentiment zien waar er wel een is: Er komen veel sentimenten in teksten voor, die mijn sentiment-analyse niet herkent als sentimenten. Soms komt dat doordat de lijst met sentimenten die ik gebruik niet volledig is. Het woord ‘genereus’ staat er bijvoorbeeld niet in. Dit zou ik met de hand kunnen toevoegen, maar wanneer hou je op met aanvullen? Soms komt dit ook doordat taal heel lastig is, en de functie die ik heb geschreven om sentimenten aan onderwerpen te koppelen bepaalde zinsconstructies niet kan herkennen. Dit is zeker iets om naar te blijven kijken als taaltechnologie zich blijft verbeteren.
Ok, toch één voorzichtige conclusie
Ondanks al deze beperkingen is het toch mogelijk om rond te kijken in de data en enigszins generalistisch iets te zeggen over sentimenten.
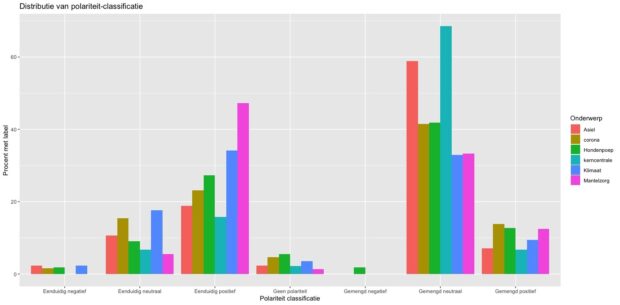
Zo blijkt bijvoorbeeld dat de volledige nieuwsberichten van politieke partijen bijna altijd positief of neutraal zijn. De teksten kunnen wel negatieve sentimenten bevatten op een bepaald onderwerp, maar de overgrote meerderheid van de sentimenten in de tekst zijn meestal positief.
Ik heb zes semi-willekeurige onderwerpen geanalyseerd (met 100 teksten elk). Daar is dezelfde verdeling te zien: de meeste teksten zijn gemengd neutraal (positieve en negatieve uitingen), daarna komen de eenduidig positieve teksten (vooral positieve uitingen). Teksten zijn eigenlijk nooit negatief (gemengd of eenduidig). Dit is onafhankelijk van het onderwerp, zoals te zien is in de staafgrafiek hieronder.
Kijk met ons mee!
Natuurlijk valt er te twisten over onder meer de categorisatie: waar leg je precies de grens tussen gemengd neutraal en eenduidig positief? Maar dan nog blijft het sterke verschil tussen de hoeveelheid positieve en de negatieve berichten opvallend.
Hoe dan ook: het is duidelijk dat er nog een lange weg te gaan is met betrekking tot sentiment-analyse. Er zijn nog teveel fouten en beperkingen om er blind (of zelfs slechtziend) op te varen. Maar geautomatiseerde sentiment-analyse is wel bruikbaar om snel een indicatie te krijgen van wat verschillende lokale politieke partijen zeggen over een onderwerp (en dat later misschien te vergelijken met wat er in hun verkiezingsprogramma staat) of als manier om te beginnen aan een onderzoek over woordgebruik door politici.
Ben jij zelf op ideeën gekomen? Wat vinden lokale partijen over onderwerpen die jij belangrijk vindt? Ga zelf aan de slag met sentiment-analyse en vindt sentimenten op specifieke onderwerpen op (https://wie.poliflw.nl), kijk naar de sentiment-classificaties op (https://poliflw.nl), of clone de repo op github (https://github.com/aludi/wieVindtWatWaarvan). En laat het ons vooral weten!
Hoofdafbeelding van Gerd Altmann via Pixabay